
Last updated: March 2026
Real-time fraud detection is fundamentally a data problem. Every transaction triggers a decision that requires synthesizing dozens of signals simultaneously: behavioral history, device fingerprints, transaction patterns, network relationships. That decision needs to be made before the transaction clears.
The tools used to make that decision have evolved significantly. Rule-based systems were the first approach. Machine learning followed. Today, the most effective fraud programs combine both, applied in a deliberate sequence that maps to the specific characteristics of each risk signal.
According to the Nasdaq Verafin 2026 Global Financial Crime Report, fraud, scams, and bank fraud losses totaled $579.4 billion globally in 2025, with fraud scam losses growing at a compound annual rate of 19.3% over the past two years. Ninety percent of financial crime professionals reported an increase in AI-driven attacks at their institution over that period. Staying ahead of that trajectory requires detection logic that adapts faster than adversarial patterns.
This post explains the trade-offs between rules and machine learning, outlines the three stages most fraud programs move through as they mature, and covers what an effective platform needs to support each stage.
TL;DR
Fraud, scams, and bank fraud losses totaled $579.4 billion globally in 2025, with fraud scam losses growing at 19.3% annually, according to the Nasdaq Verafin 2026 Global Financial Crime Report
Rules respond quickly to known patterns but degrade as adversaries adapt to thresholds
Machine learning detects complex multi-dimensional patterns but is slower to adapt and harder to explain
The most effective approach combines both: ML to identify patterns rules cannot express, rules to backstop ML where confidence is uncertain
Most programs mature through three stages: replacing select rules with ML models, backstopping ML with rules, and integrating multiple ML model scores
Real-time fraud decisioning requires all of these capabilities to operate on the same data pipeline at transaction speed
The fraud landscape today
The scale and speed of fraud have both increased materially. The Nasdaq Verafin 2026 Global Financial Crime Report found that global illicit financial activity surged to $4.4 trillion in 2025, up from $3.1 trillion in 2023. Fraud, scams, and bank fraud losses alone totaled $579.4 billion. Scam losses are growing more than twice as fast as traditional bank fraud, driven by the widespread use of AI by criminal networks.
Late detection amplifies the damage. Losses identified after the fact are substantially harder to recover, and the reputational impact on institutions that fail to protect customers compounds over time.
The core challenge is speed. Real-time payment rails and always-on digital channels have removed the window that once allowed post-event detection to work. Effective fraud mitigation now requires instant decisioning: evaluating hundreds of signals from the incoming transaction and from behavioral history, and returning a decision before the transaction clears.
Why a pure rules-based approach is insufficient
Rules work by flagging transactions that exceed predefined thresholds. If a billing address does not match the card's registered address, or login failures exceed a set count within a time window, a rule fires and an action is taken.
This approach has clear strengths: rules are transparent, fast to write, and easy to update when a new fraud pattern emerges. But they have a fundamental limitation — they are only as effective as the human insight behind them.
As adversaries learn to operate within rule thresholds, detection rates drop. Maintaining accuracy requires continuous tuning: adjusting boundaries, adding edge cases, layering conditions. This creates an increasingly brittle rule set that grows harder to manage over time.
More fundamentally, rules cannot detect patterns that span multiple dimensions simultaneously. A billing address mismatch is a strong single-variable signal. But fraud that only emerges when transaction amount, device history, location, account age, and velocity are evaluated together requires a different approach.
Why a pure machine learning approach is also insufficient
Machine learning addresses the multi-dimensional pattern problem. A well-trained model can synthesize transaction amount, device history, location data, account age, and dozens of other signals into a probability score that no rule set could replicate.
But ML has its own limitations. First, it is not agile. Training a new model takes time, making ML poorly suited to responding to fraud patterns that emerge overnight. By the time a model is retrained and deployed, adversaries may have already adapted.
Second, ML models are opaque. The probability score a model returns is a function of weights and features that most analysts cannot directly inspect. This limits who can tune the model and complicates explaining decisions for adverse action notices or regulatory review.
Third, ML models at high recall tend to generate elevated false positive rates. Finding the right operating point — enough recall to catch fraud without blocking legitimate users — requires careful calibration and ongoing monitoring.
Matching the approach to the decision
The choice between rules and ML is not binary. It depends on two variables: how complex the decision logic is, and how frequently it needs to change.
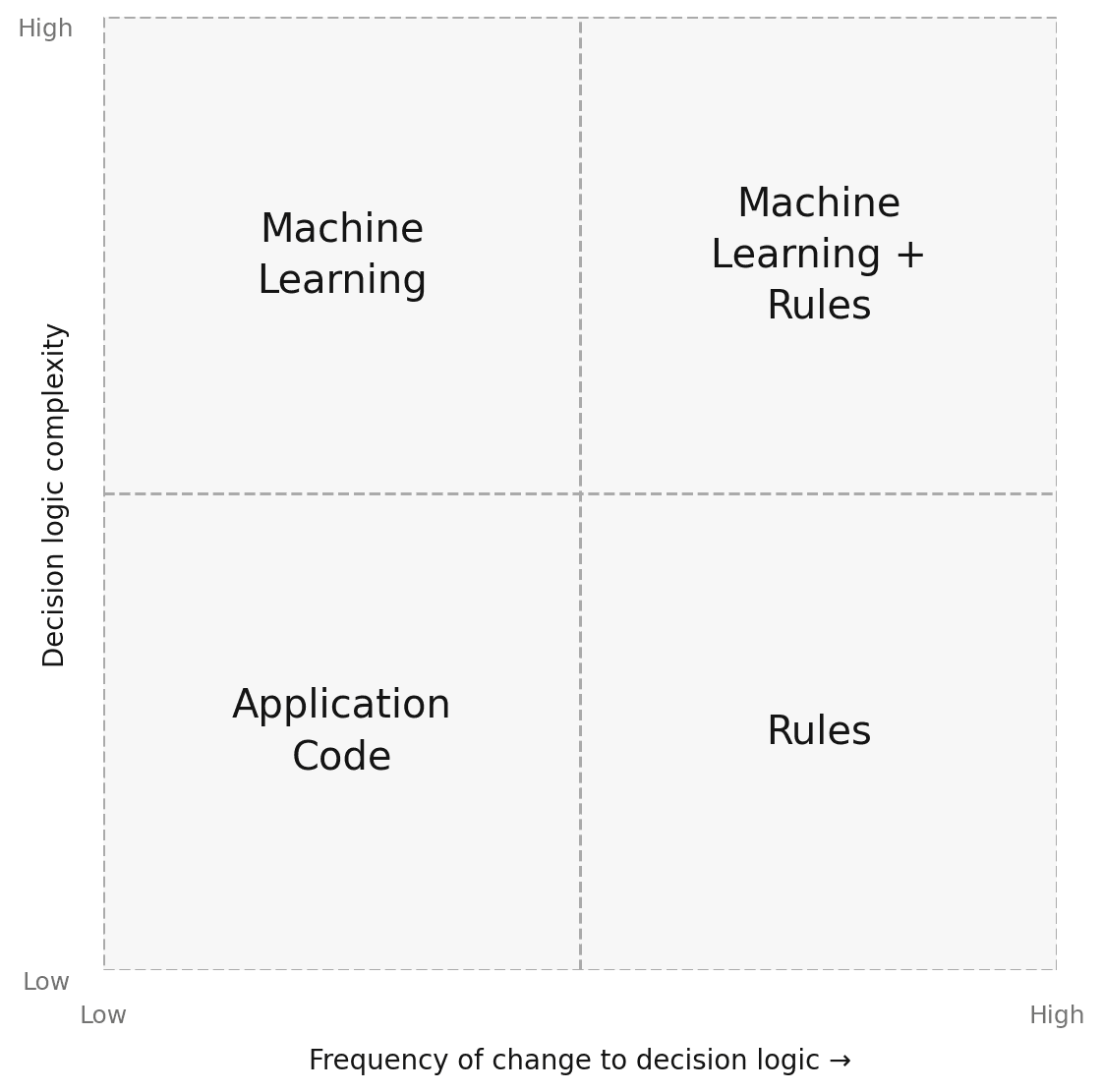
Matching detection approach to decision complexity and rate of change
Application code works for simple logic that rarely changes. A rules engine handles logic that changes frequently but stays relatively straightforward. Machine learning fits complex patterns where the rate of change is lower and sufficient training data exists. When both complexity and rate of change are high, combining ML and rules is most effective.
Beyond complexity and rate of change, the choice also involves explainability, precision of output, and where the decision logic originates. Rules produce explicit, auditable logic. ML models produce probabilistic scores that require interpretation and ongoing performance monitoring.
The three stages of combining ML and rules
Most organizations do not arrive at an integrated ML and rules approach in one step. They move through a sequence of stages, each building on the last.
Stage 1: Replace a subset of rules with ML models
The first stage is to identify rules that have accumulated complex, manually tuned thresholds and replace them with ML models trained on the same features.
Consider two rules: one that blocks requests when a user fails login three times within 30 minutes and their account is under two days old, and another that triggers step-up authentication when the transaction billing zip code does not match the customer profile. The features behind these rules — failed login count, account age, zip code — become training inputs for a transaction fraud ML model that returns a probability score. A fraud analyst then defines the action threshold.
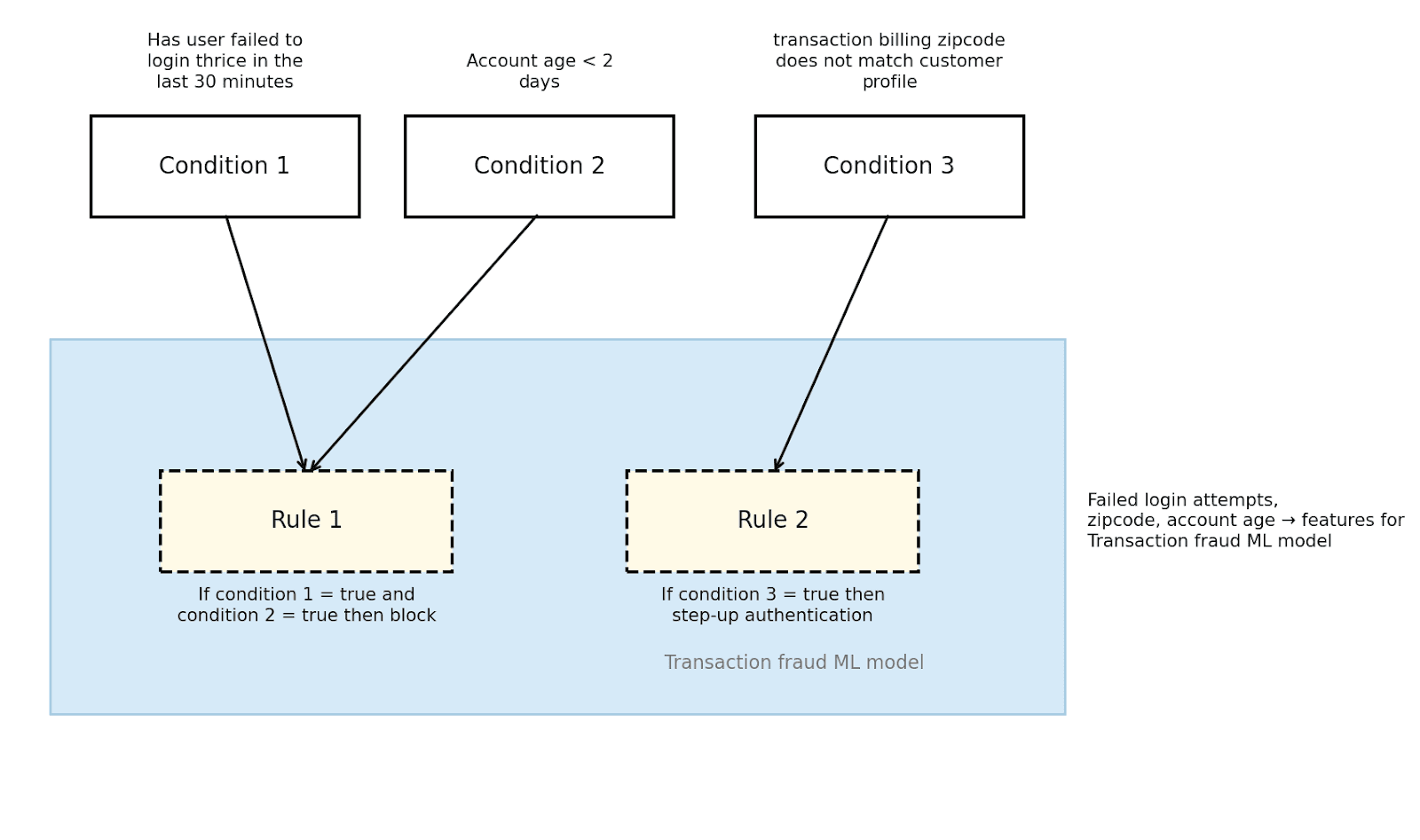
Stage 1: Rules and their features become inputs for an ML model
This approach improves recall and reduces the maintenance burden of brittle rule logic. The ML model can detect combinations of signals the rules would have missed individually.
Stage 2: Backstop ML models with rules
The second stage applies well-tuned rules alongside ML model scores. This is particularly effective during the calibration period of a new model, or when a key signal was not available during training.
For example: block the transaction if the credit card transaction ML model score exceeds 0.81 and account age is greater than 10 days, or if the score falls between 0.55 and 0.81 and account age is 10 days or less. This pattern tightens the decision boundary in the gray area, where probability scores alone generate too many false positives.
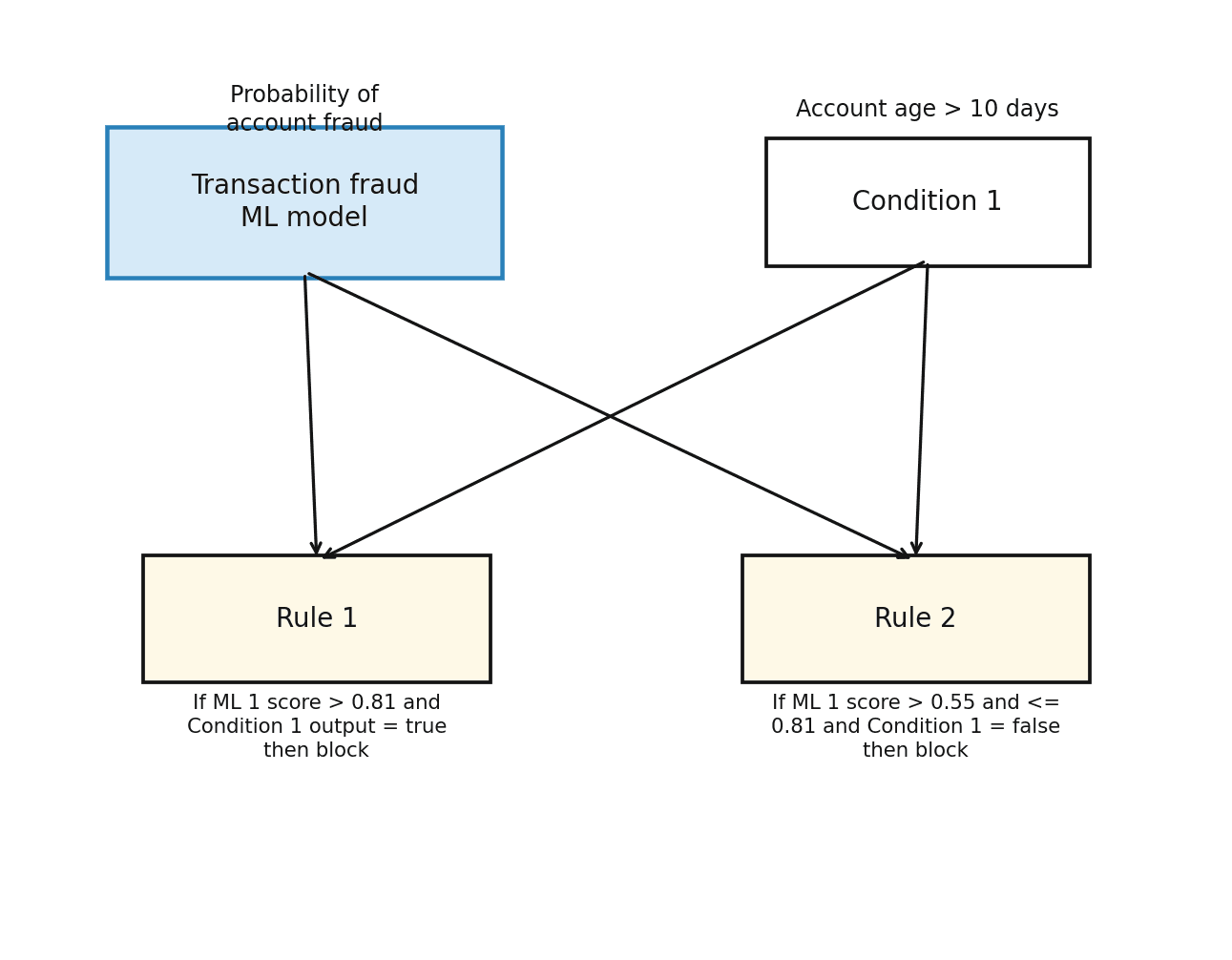
Stage 2: ML model scores combined with rule-based conditions
Rules are also a corrective layer when model performance degrades due to data drift. If fraud patterns influenced by account age begin changing faster than the model has learned, a rule incorporating that signal maintains accuracy until retraining is complete.
Stage 3: Integrate multiple ML model scores
In the most mature stage, probability scores from multiple specialized models — some internal, some from third-party providers — are combined in a single decisioning workflow.
An organization might operate an account fraud model and a transaction fraud model alongside a third-party device reputation score. These outputs feed into a workflow that combines them via rules at first, and eventually via a meta-model trained on the outputs of the component models. This produces a holistic risk assessment that no single model could generate alone.
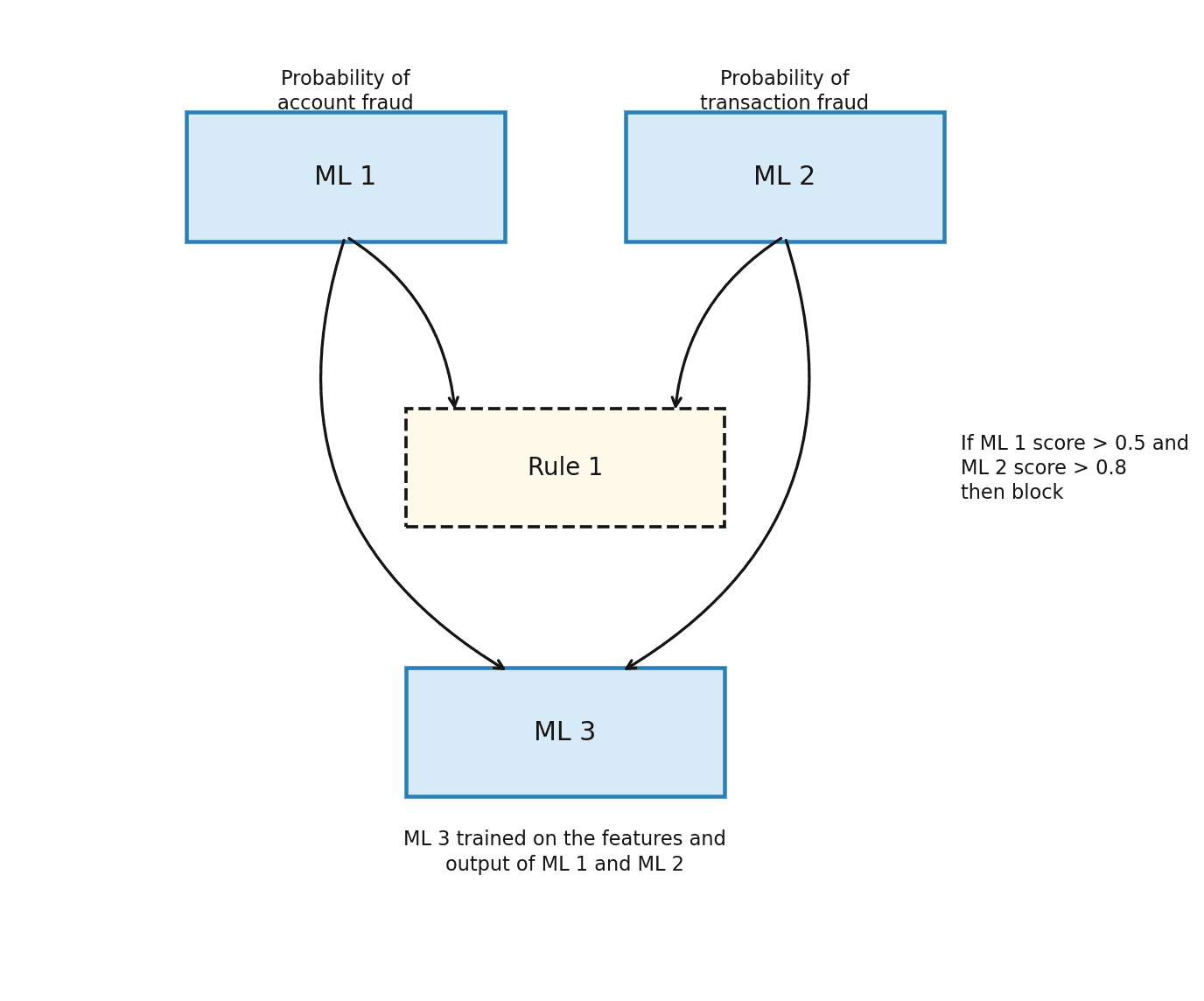
Stage 3: Multiple ML model scores integrated into a unified decisioning workflow
What a platform needs to support this evolution
Operating effectively across all three stages requires a platform with specific capabilities working together:
A shared feature store so rules and ML models operate on the same data at the same time
A customizable rules engine that can incorporate ML model scores alongside raw transaction signals
Tools to train, deploy, and monitor ML models without requiring separate data science infrastructure for every change
Backtesting against historical data to validate new logic before it affects live decisions
No-code tooling so fraud analysts can write and tune rules without engineering support
Real-time data pipelines that make features available to both rules and models at transaction speed
Oscilar's AI Risk Decisioning platform is built to support this combination. Teams can run custom ML models alongside a no-code rules engine, sharing the same feature data across both. New logic can be backtested in minutes and deployed in shadow mode before going live. The platform executes more than 700,000 real-time decisions per day, each completed in under 800 milliseconds.
Coast cut manual review time by 75 percent after implementing Oscilar's integrated case management, with automated data surfacing allowing entry-level reviewers to work independently from senior analysts. Faster investigation completes the loop: detection is only as effective as the speed at which identified fraud is acted on.
FAQs: Machine learning vs. rule based engines
When should I use rules vs. machine learning?
Use rules for high-confidence, clearly defined signals that need to respond quickly to new patterns. Use ML for complex, multi-dimensional behaviors where sufficient training data exists and the pattern is relatively stable. In most production fraud programs, both are needed and the balance shifts over time.
How do I know if my ML model is degrading?
Monitor detection rates, false positive rates, and alert volumes over time. Significant drift in any of these metrics relative to baseline performance typically indicates data shift or changes in fraud behavior that the model has not yet learned.
Can rules and ML models share the same data?
Yes, and they should. Separating the feature data used by rules from the data used by ML models is one of the most common sources of accuracy problems in fraud programs. Platforms that maintain a shared feature store eliminate this disconnect and improve consistency between rule-based and model-based decisions.
How does Oscilar support the ML and rules approach?
Oscilar's platform allows teams to combine custom ML models with a no-code rules engine using shared features. New rules and models can be backtested against historical data and deployed gradually. See the full set of capabilities on the Oscilar platform page.
See Oscilar in action
Accurate real-time fraud decisioning requires both ML and rules — applied at the right stage, operating on the same data, and deployable without engineering bottlenecks. Explore how Oscilar's platform supports this approach, or request a demo to see it in practice.







" height="48px" id="Qi9pnIQwR" width="48px"/></g></svg>)
" height="39.77194px" id="A8r2uGwai" transform="translate(2 3.808)" width="44px"/></svg>)


